
我当业余面试官的那些事儿
今年开年之后,公司例牌走了一些人,需要招几个初中级别的前端队友。
为了统一面试的水平,并且去年的项目在年底的时候已经在准备收尾,新的项目还在沟通需求,我的开发任务不多,所以被迫营业,从此走上了业余面试官的不归路。
记得第一次被叫去当面试官的时候,我比面试者还要紧张,不知道该如何问?或者问些什么?怎么去判断面试者的水平?
经过一次又一次的面试(被人叫过我去问尤雨溪;问一句,Ta回一句不超过十个字的回答的尴尬场面),让人等通知的过程,同时也在网上找了一些面试题,慢慢地我总结了一些面试的套路。
套路
答案可能并不标准,仅代表我个人的观点,不喜请喷!
css相关
都是随便问问,css不过关我也不会深究
css盒模型
我想知道什么?
- 什么是盒模型?或者说盒模型它包含了什么?
- 有几种盒模型?
- 它们有什么特点?
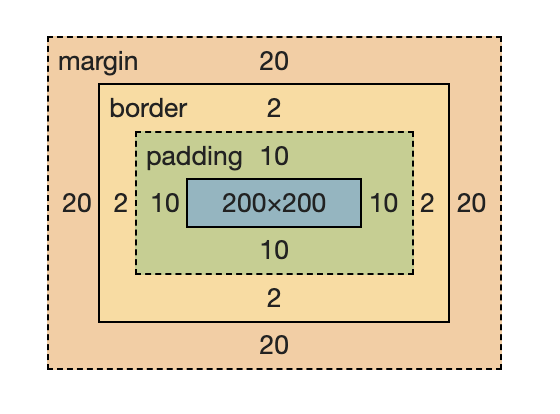
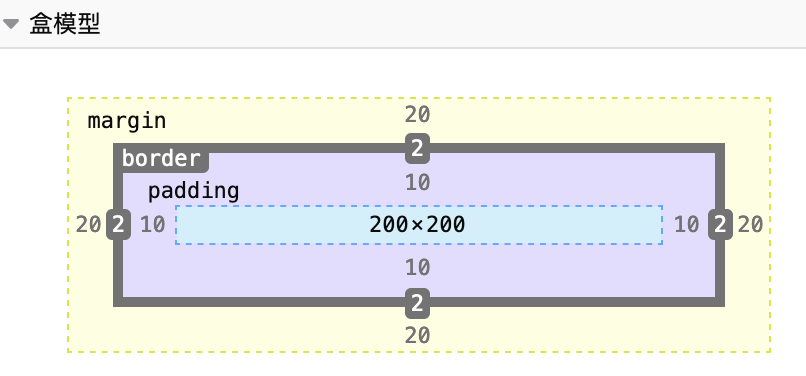
以上是 firefox 和 chrome 两个浏览器控制台展示的盒模型,我们可以很清晰地看到盒模型从内往外包含了:内容(content)、内边距(padding)、边框(border)和外边距(margin)这四项。
盒模型有标准盒模型(content-box) 和怪异盒模型(border-box)两种。可以通过 css 的 box-sizing 规则设置使用不同的盒子模型:
css
box-sizing: content-box; /* 默认,标准盒模型 */
box-sizing: border-box; /* ie盒模型,也称为怪异盒模型 */
标准盒模型
在标准盒模型中,你设置的 width / height 属性,实际上是设置了 content。
border 和 padding 加上设置的 width、height 决定了整个盒子的大小:
- 标准盒模型的宽度 =
border-left+padding-left+width+padding-right+border-right; - 标准盒模型的高度 =
border-top+padding-top+height+padding-bottom+border-bottom;
注意:margin 不计入实际大小。当然,它会影响盒子在页面中占据的空间,但影响到的是盒子外部的空间。盒子的范围到 border 为止,不会延伸到 margin。
怪异盒模型
通常情况下,我们计算一个盒子的大小还需要加上 border 和 padding,这样子会很麻烦。因为这个原因,css还有一个替代盒模型——也就是怪异盒模型。使用这个模型,盒子的大小会等于你设置的 width / height 的值。
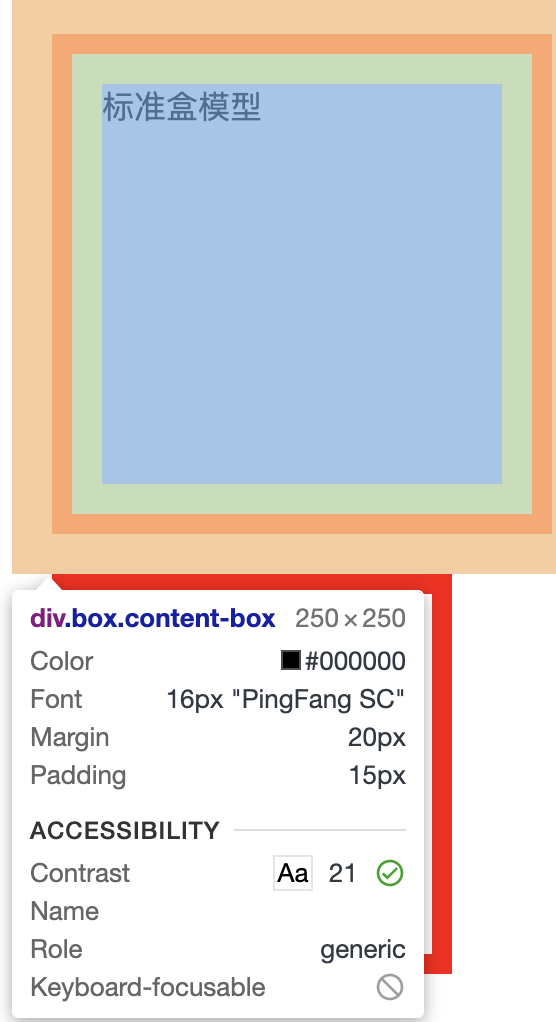
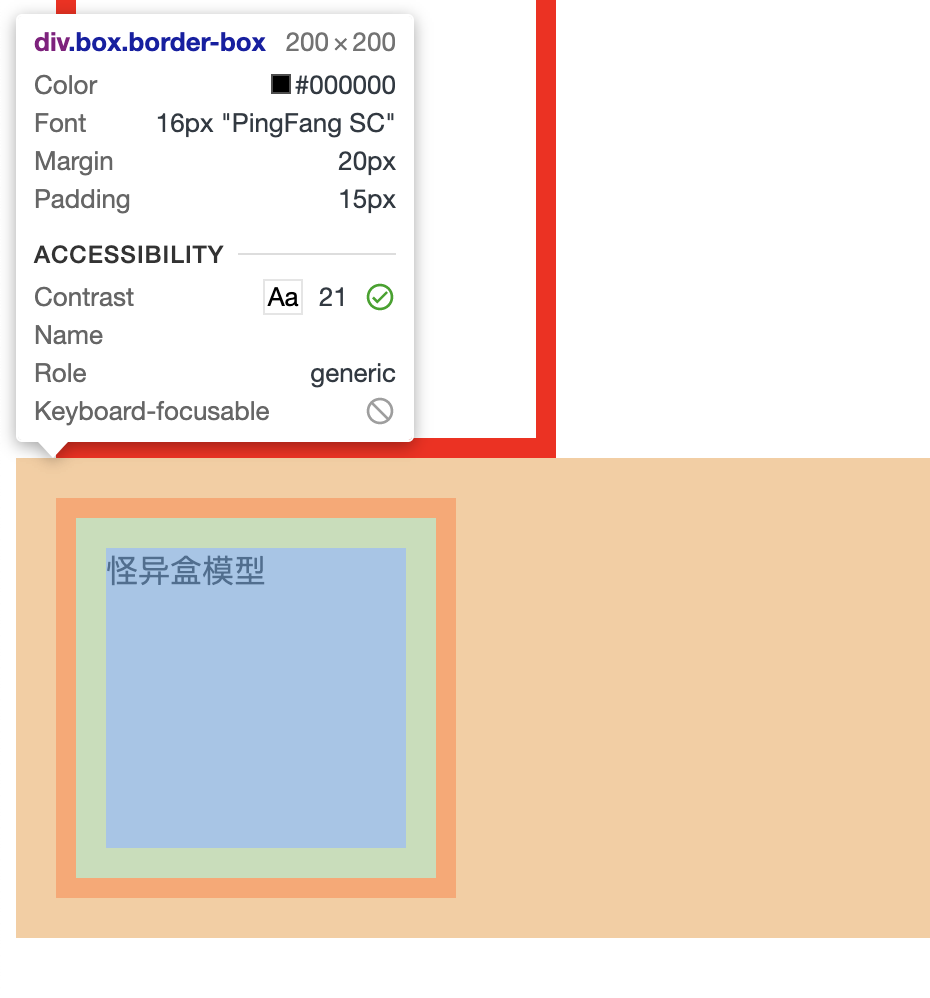
我们看一下两种盒子模型的大小对比:
html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>盒子模型</title>
<style type="text/css">
.box {
width: 200px;
height: 200px;
margin: 20px;
padding: 15px;
border: 10px solid red;
}
.content-box {
box-sizing: content-box;
}
.border-box {
box-sizing: border-box;
}
</style>
</head>
<body>
<div class="box content-box">标准盒模型</div>
<div class="box border-box">怪异盒模型</div>
</body>
</html>
从上面的代码我们分析一下大小:
- content-box 的宽度 = 10px(border-left) + 15px(padding-left) + 200px(width) + 15px(padding-right) + 10px(border-right) = 250px;
- border-box 的宽度 = 200px(width)。
rem 和 em 的区别
我想知道什么?
- rem 是什么?
- em 是什么?
- 它们两个的区别
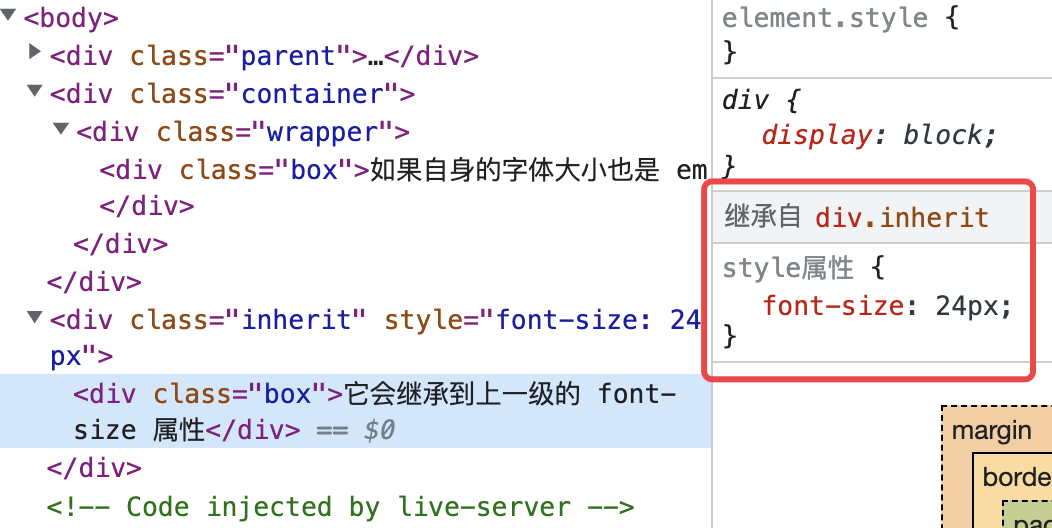
rem 是一个相对 HTML 的根元素 font-size 的尺寸单位;em 是相对元素自身的 font-size 的尺寸单位。它们的区别就在于参照元素不一样。
注意:em 是相对自身的字体大小,很多人都说它是相对父元素的字体大小,其实不是的。
我们看下面的例子:
html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>em</title>
<style type="text/css">
.parent {
font-size: 20px;
}
.children {
font-size: 40px;
padding: 1em;
}
.container {
font-size: 20px;
}
.container .wrapper {
font-size: 1.5em;
}
.container .wrapper .box {
font-size: 2em;
padding: 1em;
}
</style>
</head>
<body>
<div class="parent">
<div class="children">em 是一个相对自身字体大小的尺寸单位!</div>
</div>
<div class="container">
<div class="wrapper">
<div class="box">如果自身的字体大小也是 em</div>
</div>
</div>
</body>
</html>

我们可以看到 children 的 padding 值是 1em ,转换成 px 则是 1 * 40px = 40px,而不是父元素字体大小的 20px。
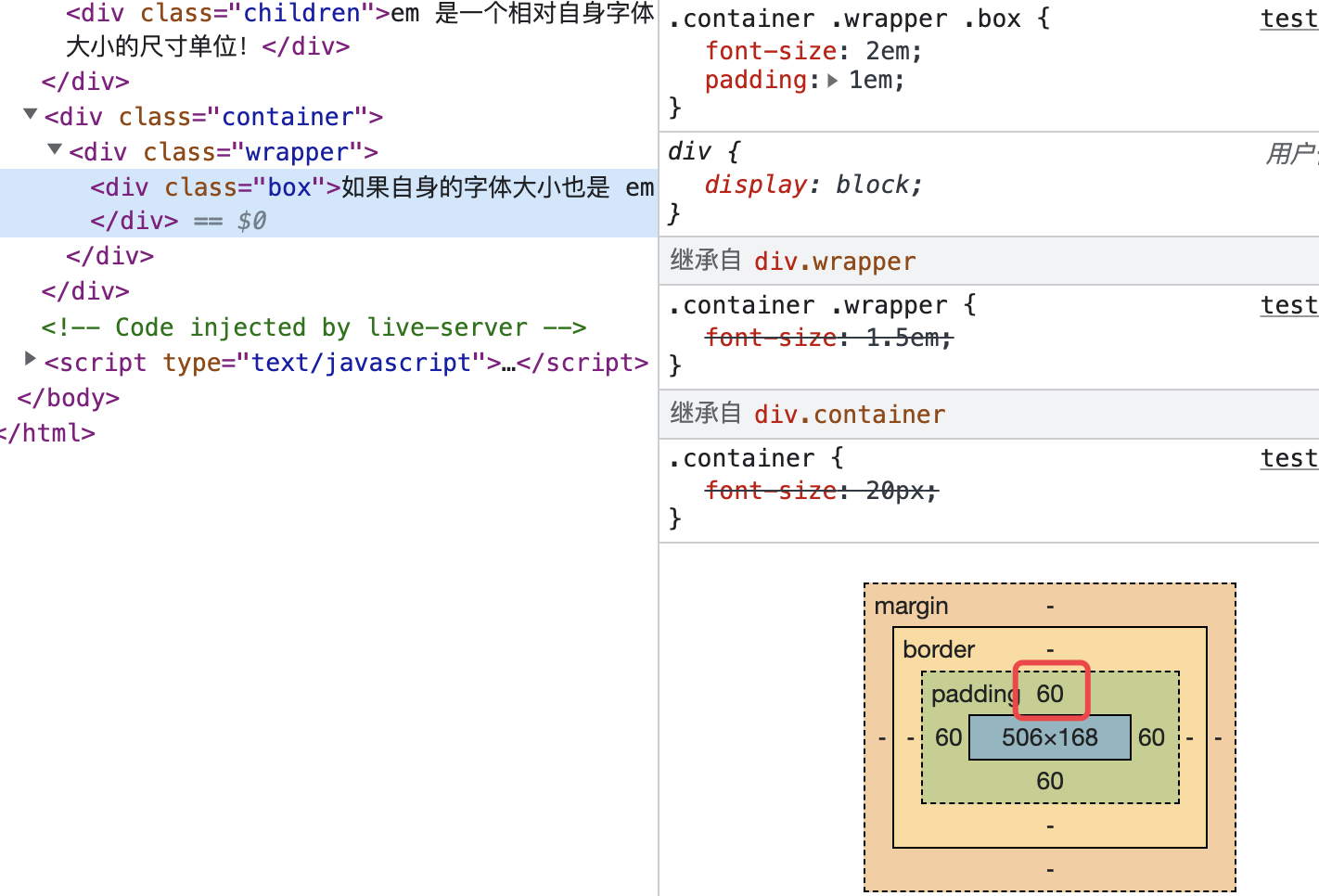
box 的 padding 是 60px,这是怎么转换过来的呢?
- container 的
font-size是 20px; - 因为 wrapper 的
font-size是一个相对单位(em),所以它会取父元素的font-size来计算,也就是1.5 * 20px = 30px; - box 的
font-size也是一个相对单位(em),同理,它的font-size为2 * 30px = 60px,所以padding是60px。
只有当自身的字体大小也是 em 的时候,才会找上一级的 font-size ,直到找到一个它能计算的参照值为止。之所以会造成 em 是相对父元素字体大小的错觉,是因为当自身没有设置相应的 css 属性,它会继承上一级的属性。
flex: 1 是什么意思
我想知道什么?
- flex 这个属性是什么?
- flex: 1; 的结果会是什么?
具有内容看 mdn
HTML5相关
HTML5 这一块,我一般都会先问了解多少 HTML5 的新特性,然后随便挑一两个来问问。
cookie、localStorage 和 sessionStorage 的区别
| - | Cookies | Local Storage | Session Storage |
|---|---|---|---|
| 容量 | 4KB | 5MB | 5MB |
| 兼容性 | HTML4/HTML5 | HTML5 | HTML5 |
| 可访问性 | 任意窗口 | 任意窗口 | 当前标签页 |
| 过期时间 | 可手动设置 | 永不过期 | 标签页关闭 |
| 存放位置 | 浏览器和服务器 | 浏览器 | 浏览器 |
| 请求携带 | 是 | 否 | 否 |
EcmaScript 相关
数据类型
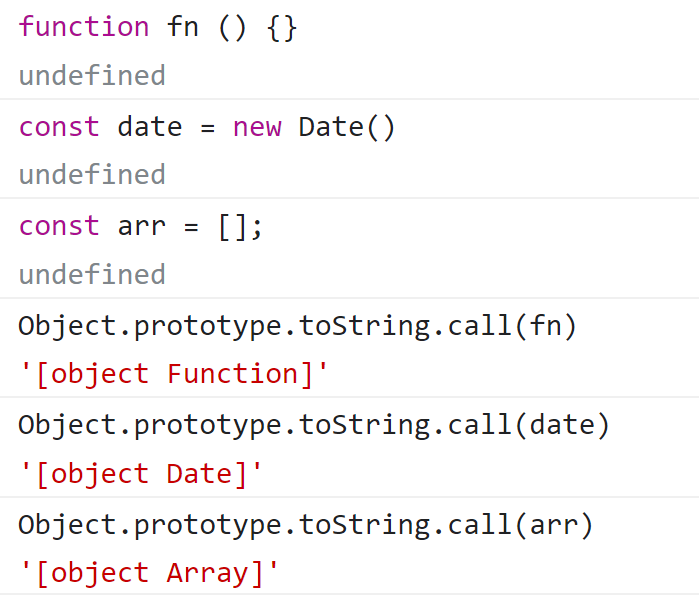
求求你们,别再说什么 array function date 了,它们都是对象类型(object);
- 基本类型:string、number、boolean、null、undefined、symbol、bigInt
- 引用类型:object
需要注意的是,很多人都在引用类型上面说还有 array、function、date 等,其实他们都是属于 object 类型:
原型和原型链
我想知道什么?
- 原型是什么?
- 原型链是什么?
那么原型是什么呢?
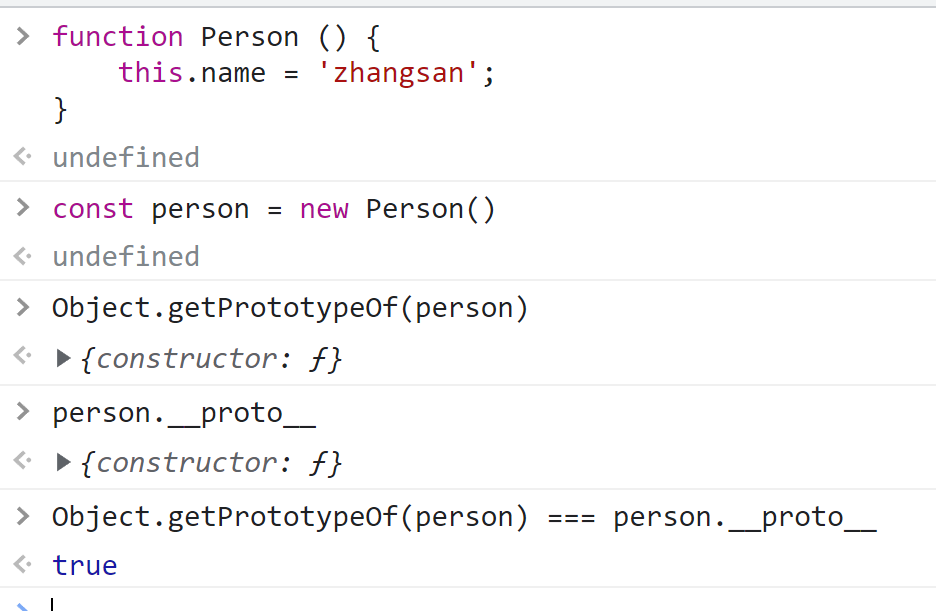
英文叫 prototype,它是构造函数上的一个特殊的属性,我们可以在构造函数或者实例化对象中访问到原型上的属性或方法,它也叫显式原型,可以通过 Object.getPrototypeOf 来获取实例的显式原型。
在实例化对象中,有一个私有属性 __proto__,它是实例化对象的属性,被称为隐式原型,是由 prototype 派生的,它们俩是指向的是同一个内存引用地址。
在原型上,有一个 construtor属性,它指向构造函数。
那么什么是原型链呢?
对象在访问属性或方法的时候,会在自身寻找对应的属性或方法;如果在自身找不到,则会通过 __proto__ 去原型对象上面寻找;如果 __proto__ 上面没有,由于 __proto__ 它也是一个对象,它也有自身的隐式原型,它也会继续往它的 __proto__ (也就是 __proto__.__proto__)上面寻找;一直往上面找,直接找到了 Object.prototype 的 __proto__,它指向 null,如果最终都找不到对应的属性或方法,最终会返回 undefined。
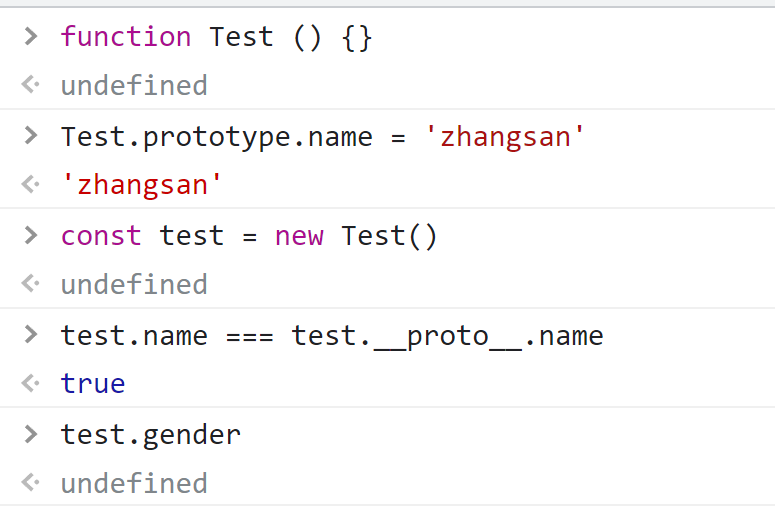
而这种通过 __proto__ 一层一层地寻找属性或方法的方式,它是一个链式的关系,也就是所谓的原型链。
原型链的终点是什么?
Nearly all objects in JavaScript are instances of
Object, which hasnullas its prototype.

闭包的理解
我想知道什么?
- 闭包是什么?
- 为什么会形成闭包?
- 闭包的弊端?
- 什么时候会用到闭包?
详细的解释请看JavaScript中的闭包现象
函数的 this 指向
我想知道什么?
- 不同情况下的 this 指向?
- 怎么改变 this 指向?
this 指向的问题需要区分普通函数和ES6的箭头函数:
箭头函数本身是没有 this 的,这也是它无法作为构造函数的原因,箭头函数会从它作用域链的上一层继承 this:
js
function Person () {
this.age = 10
setTimeout(() => {
this.age++ // this 指向上一层作用域
}, 1000)
}
const person = new Person()
console.log(person.age) // 10
// 1秒后
console.log(person.age) // 11
普通函数的 this 指向分为以下几种情况:
- 如果该函数被作为构造函数,this 指向实例化对象;
- 非严格模式下,函数自调用时 this 指向 window 或 global;
- 严格模式下,函数自调用时 this 是 undefined;
- 调用对象下的函数,this 指向该对象;
- 通过 call、apply 或 bind 调用时,this 指向第一个传入的参数。
js
// 第1种情况
function Person () {
this.a = 1
}
const p = new Person()
console.log(p.a) // 1
// 第2种情况
var a = 2;
function test () {
console.log(this.a)
}
test(); // 2
// 第3种情况
(function () {
'use strict';
function fn () {
console.log(this);
}
fn(); // undefined
})();
// 第4种情况
const obj = {
a: 4,
fn () {
console.log(this.a)
}
}
obj.fn(); // 4
// 第5种情况
function test5 () {
console.log(this.a)
}
const ctx = { a: 5 }
test5() // 2
test5.call(ctx) // 5
call、apply 和 bind 的区别
我想知道什么?
- 它们的区别?
- bind 的一些特点
call、apply 和 bind 三者的相同点都是可以改变函数的 this 指向,并且第一个参数都是需要改变的上下文对象。
它们的不同点在于:
- call 的第2个参数开始,都是需要传递给 fn 的参数,且是立即执行 fn;
- apply 的第2个参数是一个需要传递给 fn 的参数数组(或者其它具有
iterator接口的数据类型),且是立即执行 fn; - bind 的参数和 call 一样,返回一个已经改变 this 指向的新函数。
js
function fn (name, age) {
console.log(this.a, name, age)
}
const ctx = { a: 1 }
fn.call(ctx, 'zhangsan', 12) // 1 'zhangsan' 12
fn.apply(ctx, ['lisi', 16]) // 1 'lisi' 16
const fn2 = fn.bind(ctx, 'wangwu', 18)
fn2(); // 1 'wangwu' 18
需要注意的是,bind 可以分步传参的:
js
function fn (name, age) {
console.log(this.a, name, age)
}
const ctx = { a: 1 }
const fn2 = fn.bind(ctx)
fn2('wangwu', 18) // 1 'wangwu' 18
const fn3 = fn.bind(ctx, 'wangwu')
fn3(18) // 1 'wangwu' 18
构造函数被实例化的时候内部发生了什么
我们先看下面的例子:
js
function Person (name, age) {
this.name = name;
this.age = age;
}
const p = new Person('zhangsan', 18)
console.log(p.name, p.age) // 'zhangesan' 18
那么在实例化的时候,内部发生了什么呢:
- 创建一个空对象;
- 为空对象添加一个
__proto__属性,并将构造函数的原型对象赋值给__proto__; - 把 this 赋值给这个空对象;
- 最后返回这个空对象。
需要注意的是,构造函数显式返回一个引用类型的数据时,实例化对象将会是这个被返回的引用数据类型:
js
function Person (name, age) {
this.name = name;
this.age = age;
return {
name: '张三',
age: 10
}
}
const p = new Person('zhangsan', 18);
console.log(p.name, p.age) // '张三' 10
如果,构造函数显式返回一个基本类型的数据时,那么实例化将不会被影响到:
js
function Person (name, age) {
this.name = name;
this.age = age;
return '张三'
}
const p = new Person('zhangsan', 18);
console.log(p.name, p.age) // 'zhangsan' 18
函数默认的返回值是 undefined,它也是一个基本类型的数据。
尝试一下手写一个函数,实现一个 new:
js
function myNew (Fn, ...args) {
if (typeof Fn !== 'function') {
throw new TypeError(`${Fn} is not a constructor`)
}
if (typeof Fn.prototype === 'undefined') {
throw new TypeError(`${Fn.name} is not a constructor`)
}
const instance = Object.create(Fn.prototype)
const ret = Fn.apply(instance, args)
return typeof ret === 'function' || (typeof ret === 'object' && ret !== null)
? ret
: instance
}
function Male (name) {
this.name = name
}
Male.prototype.gender = 'male'
Male.prototype.display = function () {
console.log(this.name, this.gender)
}
const m1 = new Male('zhangsan')
m1.display() // 'zhangsan' 'male'
const m2 = myNew(Male, 'lisi')
m2.display() // 'lisi' 'male'
var、let 和 const 的区别
详细区别请看:let,var和const三者的区别
for…of 和 for…in 的区别
for…in 语句会以任意顺序迭代一个对象的可枚举属性(除了 Symbol),以及它原型上的所有可枚举属性。
for…in 是为了遍历对象属性而创建的,不建议使用 for…in 来遍历数组,除了有其它的遍历方式之外,使用 for…in 来遍历数组还会有以下弊端:
- 数组本身的索引是数字类型的值,使用 for…in 会是字符串类型的值;
- for…in 遍历顺序混乱。
for…of 语句是ES6在借鉴了 C++ 、Java 、C# 等语言,引入的一种遍历所有数据结构的统一方法,只要这个数据结构部署了 Symbol.iterator 属性(也就是该数据结构具有 iterator 接口),那么它就可以使用 for…of 进行遍历。for…of 语句内部是调用了数据结构中的 Symbol.iterator 方法。
Promise 和 async/await
我想知道什么?
- Promise 是什么?
- Promise 有什么特点?
- Promise 的常用静态方法和原型上的方法。
- async/await 是什么?
Promise 用于表示一个异步操作的最终状态(完成或失败)及其结果值。
Promise 是一个回调嵌套(回调地狱)编码方式的解决方案,它在 JavaScript 语言中早有实现,ES6将其写入标准,统一了用法,并提供了原生的 Promise。
Promise 有两个特点:
- 状态不受外界影响:Promise 它代表着一个异步操作,有3种状态,分别是进行中(Pending)、已成功(Fulfilled/Resolved)和已失败(Rejected)。只有异步操作的结果能决定当前是哪一种状态,任何操作也无法改变这个状态。这也是 Promise 这个名称的由来;
- 状态一旦发生改变,就不会再改变,并且在任何时候都能获得这个结果。Promise 的状态改变只有两种:Pending 变成 Fulfilled;或者是 Pending 变成 Rejected。只要其中之一发生了,状态就会被凝固,不会再改变。
Promise 是一个构造函数,它接收一个回调函数(Executor)作为参数,通过 new 调用生成一个 Promise 实例;Executor 有两个参数:resolve 和 reject,resolve 在异步操作成功完成时调用,将 Promise 的状态从 Pending 变成 Fulfilled,并且可以将成功的结果传递出去;reject 在异步操作失败时调用,将 Promise 的状态 从 Pending 变成 Rejected,并且可以将失败的信息传递出去。下面是一个 Promise 的示例:
js
const promise = new Promise((resolve, reject) => {
// do sth...
if (/* 异步操作成功 */) {
resolve(result)
} else {
reject(error)
}
})
注意:虽然 Promise 它代表着一个异步操作,但是 Executor 内部的代码是同步执行的。
Promise.prototype.then 和 Promise.prototype.catch
Promise 实例生成之后可以通过 then 方法来指定成功和失败时的回调函数:
js
promise.then(
(result) => {
// 如果成功,将会走这个回调
console.log(result)
},
(error) => {
// 如果失败,将会走这个回调
console.log(error)
}
)
也可以通过 catch 方法来指定失败时的回调函数:
js
promise
.then(() => {})
.catch((error) => {
console.log(error)
})
then 和 catch 方法会返回一个新的 Promise 实例,所以我们可以链式调用相关的方法。
另外,Promise 在状态改变之后,内部发生了错误或者手动抛出一个错误时,该 Promise 的状态将会变成 Rejected:
js
const promise = new Promise((resolve, reject) => {
throw new Error('error')
resolve()
})
console.log(promise) // <rejected>
而在 Promise 状态变成 Fulfilled 之后,代码再发生错误,将不会改变 Promise 的状态:
js
const promise = new Promise((resolve, reject) => {
resolve()
throw new Error('error')
})
console.log(promise) // <fulfilled>
Promise 的错误还具有“冒泡”的性质,错误会一直向后传递,直接被 catch 捕获为止:
js
promise
.then(() => {})
.then(() => {})
.catch((error) => {
// 处理前3个 promise 可能产生的错误
})
Promise.all 和 Promise.race
Promise.all() 接收一组 Promise 实例作为参数,通常是数组(也可以是任何具有 iterator 接口的数据结构,只要它返回的都是 Promise 实例即可),它返回一个新的 Promise 实例,返回的实例状态有以下特点:
- 当参数中的所有 Promise 实例都变成 Fulfilled 状态时,
Promise.all()实例的状态变成 Fulfilled;此时所有参数实例的结果会按顺序组装成数组传递出去; - 当参数中的某个 Promise 实例变成了 Rejcted 状态时,
Promise.all()实例的状态变成 Rejected;此时参数中第一个变成 Rejected 状态的实例结果会被传递出去。
Promise.race()它的参数和 Promise.all() 一样,race 在英文中有竞赛的意思,也就是说只要参数实例中有一个实例率先改变了状态,那么 Promise.race() 实例的状态就会变成该状态,同时传递该实例的结果。
Promise.resolve 和 Promise.reject
Promise.resolve()返回一个具有 Fulfilled 状态的Promise实例;Promise.reject()返回一个具有 Rejected 状态的Promise实例。
需要注意的是:如果 Promise.resolve() 的参数是一个具有 then() 方法的对象,那么将会返回一个状态为 Pending 状态的 Promise 实例,并且参数实例中的 then() 会被执行:
js
const result1 = {
name: 'zhangsan',
age: 12
}
const p1 = Promise.resolve(result1)
console.log(p1) // <fulfilled>
p1.then(res => {
console.log(res) // { name: 'zhangsan', age: 12 }
})
const result2 = {
name: 'lisi',
age: 12,
then (res) { // 会被调用
console.log(res) // f () { [native code] }
}
}
const p2 = Promise.resolve(result2)
console.log(p2) // <pending>
const p3 = Promise.reject(result2)
console.log(p3) // <rejected>
const result4 = {
catch (err) {
console.log(err)
}
}
const p4 = Promise.reject(result4)
console.log(p4) // <rejected>
Promise.prototype.finally
finally() 方法不管 Promise 的实例如何,最终都会被执行。
async/await
async 函数是使用
async关键字声明的函数,并允许该函数中使用await关键字。async和await关键字使得我们可以用一种更为简洁的方式写出基于 Promise 的异步行为,而无需刻意地链式调用 Promise。
如果一个函数加上了 async 关键字,它的返回值必定是一个 Promise 实例:
js
async function p1 () {
return 1
}
console.log(p1) // Promise<fulfilled>
p1().then(res => console.log(res)) // 1
await 关键字后面的表达式是一个 Promise 实例,如果不会,他会调用 Promise.resolve() 包裹起来:
js
const p = new Promise((resolve, reject) => {
setTimeout(() => {
console.log('resolve')
resolve('resolve')
}, 1000)
})
async function test1 () {
console.log(1)
await p
console.log(2)
}
test1()
// 1
// 'resolve'
// 2
// test1 中的 await 可以这样理解
async function _test1 () {
console.log(1)
new Promise((resolve, reject) => {
setTimeout(() => {
console.log('resolve')
resolve('resolve')
}, 1000)
}).then(() => {
console.log(2)
})
}
async function test2 () {
console.log(1)
await console.log(3)
console.log(2)
}
test2()
// 1
// 3
// 2
// test2 相当于以下函数
async function test3 () {
console.log(1)
Promise.resolve(console.log(3))
.then(() => {
console.log(2)
})
}
更加具体的 Promise 和 async/await 相关的内容请看:Promise对象 和 异步操作和async函数。
Vue 相关
目前大部分都是问的关于 Vue2.x 版本的内容,如果对方简历上有写上 Vue3,才会简单地问一下。
生命周期
我想知道什么?
- 我就想知道你有没有看文档
Vue 的生命周期在官方文档中有着很详细的图示:
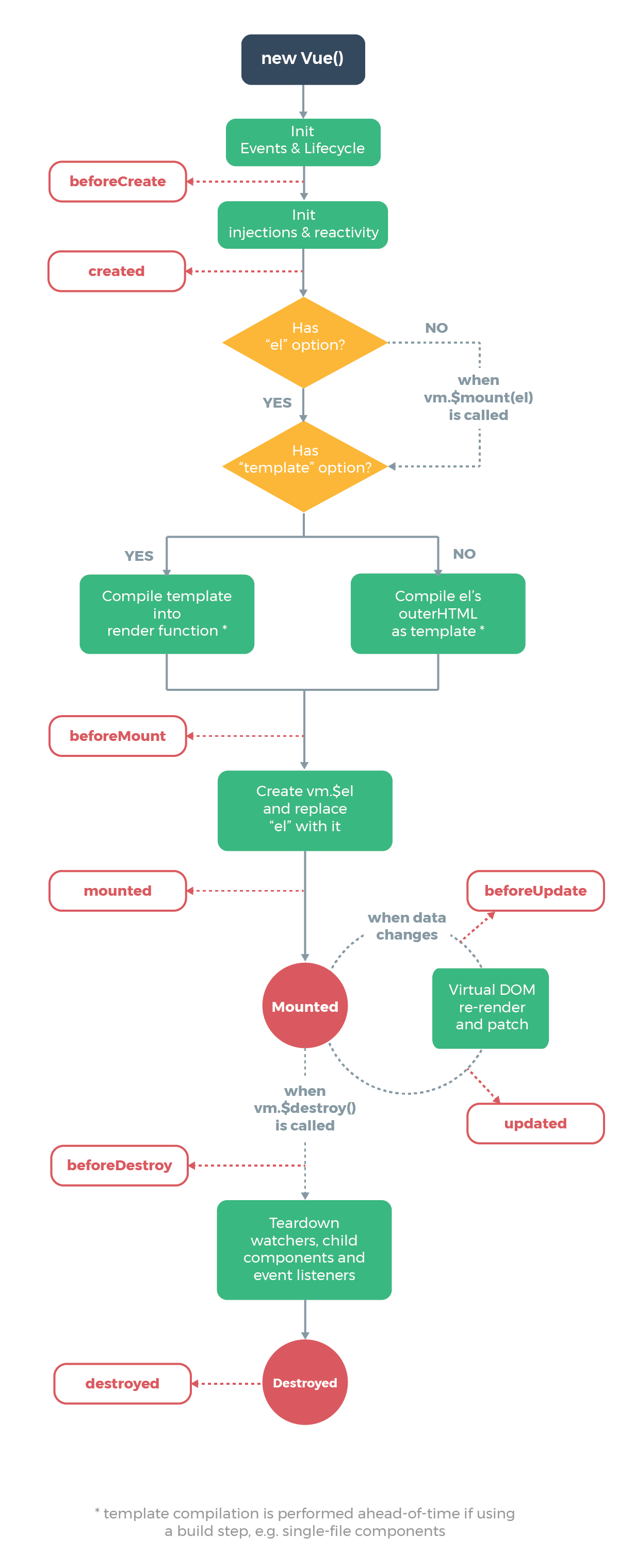
这里不得不吐槽一下,我经常听到的是这样的描述:创建前后、挂载前后、更新前后和卸载前后。我不明白对方在写的时候是不是从来都不记相关的英文,过度依赖编辑器的自动补全功能。
也有的说什么 beforeCreated、beforeMounted 等。
所以每次当他们说完之后,我都会问一下:在 beforeCreate 这个生命周期钩子里面,this 是什么?
很多人会回答是 undefined,更有甚者说是 window,相当过分。

生命周期图示中的第一步就是 new Vue(),也就是说此时的 this 就已经是 new Vue() 产生的实例化对象了。
在 beforeCreate 阶段之前,Vue 内部只作了生命周期的初始化和事件的初始化,所以此时的 this 上并没有 data、methods 等属性,所以我们暂时还不能访问到它们。
v-if 和 v-show 的区别
v-if 和 v-show 的相同点是:它们都是控制组件或者元素的显示/隐藏的。
不同点是 v-if 仅当值为 true 时,组件才会被挂载到 DOM 上面;而 v-show 会直接把组件挂载,通过控制 css 的 display 属性来显式/隐藏元素。
通常情况下,需要频繁切换的元素/组件使用 v-show,反之使用 v-if。
key 是用来做什么的
我想知道什么?
- 其实这里我只想你把 diff 算法,这个名词说出来而已
- 还有就是数组的索引作为 key 会有什么弊端
组件/元素上的 key 值作为虚拟DOM中的唯一标识,主要用在虚拟DOM的 diff算法,更详细的 key 介绍请百度或谷歌一下。
在 v-for 中使用索引作为 key 会有什么弊端?
由于数组中的索引是一个可变的值,而且在 Vue 中更新循环列表元素时,它默认使用就地更新的策略。如果数据项的顺序被改变,Vue 将不会移动 DOM 元素来匹配数据项的顺序,而是就地更新每个元素 。
我们看下面的这段代码:
html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<div id="root">
<ul class="list">
<li
v-for="(item, index) in arr"
:key="index"
class="item"
>
<label for="">
索引{{ index }},值{{ item }}: <input type="text" />
</label>
</li>
</ul>
<button @click="handleClick">删除第0项</button>
</div>
<script src="https://www.unpkg.com/vue@2.6.12/dist/vue.js"></script>
<script type="text/javascript">
const vm = new Vue({
el: '#root',
data: {
arr: [1, 2, 3]
},
methods: {
handleClick () {
this.arr.splice(0, 1)
}
}
})
</script>
</body>
</html>
同时我们看一下运行时的结果:
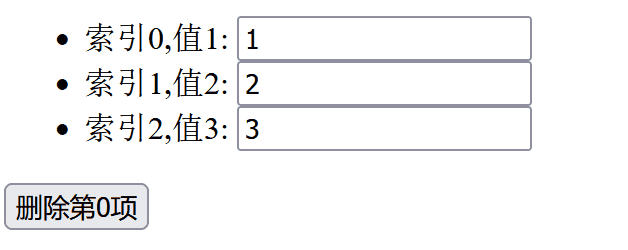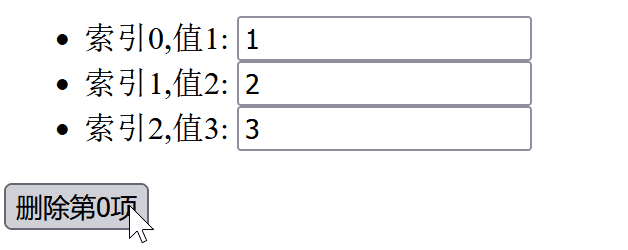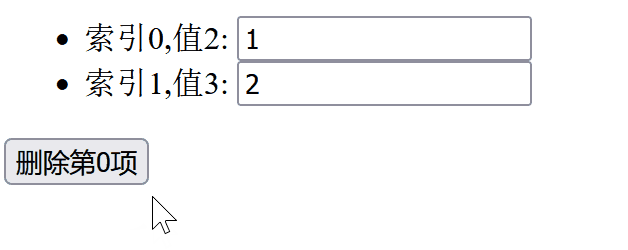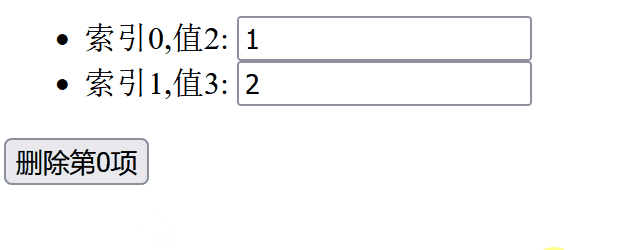
我们可以看到,当我们删除第0项时,input 框里面的内容变化令人感到困惑。所以我们需要避免使用索引作为 key。
双向数据绑定
双向数据绑定这个问题应该不难,但是我不明白为什么很多人都回答了 Vue 的响应式设计?所以很多时候我都会等他们说完了,再告诉他,其实他回答的是响应式设计,其实我想问的是 v-model。
vue 的双向数据绑定指的是 v-model 这个语法糖,具体解释看文档:v-model
嵌套组件的挂载顺序
这个也不是什么难的问题
详情请看:嵌套组件中的生命周期钩子的触发顺序
computed 和 watch 的区别
- computed 具有缓存机制
- computed 一个数据改变依赖多个数据源
- watch 一个数据源改变多个,或者做一些异步操作、DOM操作等。
Vue3 的 watch 和 watchEffect 有什么区别
这个问题一般都会在简历上看到写着Vue3相关的技术才会问到
- watch 和 watchEffect 的相同点
- 不同点
watchEffect 会立即执行它的回调函数,同时追踪其响应式依赖,并在其依赖改变时重新执行回调函数。
js
const count = ref(0)
watchEffect(() => console.log(count.value))
// 0
setTimeout(() => {
count.value++
// 1
}, 1000)
watch 需要侦听特定的数据源,并且在单独的回调函数中执行副作用。默认情况下,它是惰性的——即回调会在数据源发生变化时才会执行回调函数。
与 watchEffect 相比:
- 惰性执行副作用;
- 更具体地说明应触发侦听器重新运行的状态;
- 访问被侦听状态的先前值和当前值。
Vuex 的 mutations 和 actions 有什么区别
我想知道什么?
- 他们俩的区别?
- 为什么actions可以做一些异步操作?
我们先看看 Vuex 中的数据流
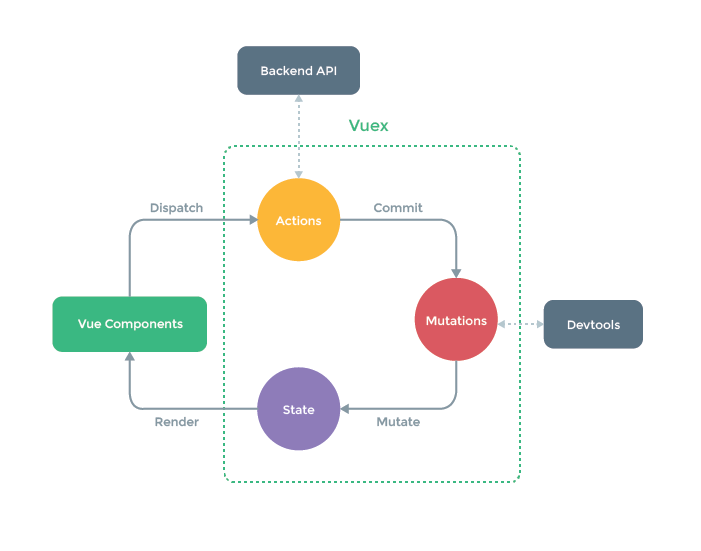
在 Vuex 文档中指出,更改 state 的唯一方法就是提交一个 mutation,并规定:mutation 必须是一个同步函数。
为什么
mutation必须是同步函数呢?因为当
mutation被触发的时候,会被 devtools 记录,并捕捉到前一状态和后一状态的快照。如果muation里面有异步操作之后再改变state,devtools 就无法知道状态是什么时候被改变的,这会让开发人员在调试程序时变得非常困难。
action 的操作的 mutation 类似,不同点在于:
action提交的是mutation,而不是直接改变state;action可以做异步操作。
为什么
action可以做异步操作呢?因为
action里面并不是直接对state修改,而是通过提交一个mutation,最终在mutation中完成对state的修改;我们会在异步操作完成之后才提交mutation,mutation里面的操作会被 devtools 记录到,不会影响到开发人员的调试。
单页面应用首屏优化
这是一个比较大的话题,大致说出一些常用的优化手段就好了。
- 使用 CDN 引入一些比较大的依赖包;
- 路由按需加载,懒加载组件;
- 不影响页面加载的逻辑移到 DOMContentLoaded 之后再引入;
- 开启代码压缩;
- 图片懒加载;
- 优先渲染第一屏内容;
- 等等…
网络相关
在浏览器中输入 URL 地址,然后回车,到页面完全渲染完毕的过程
我想知道什么?
- 浏览器请求一个页面的流程
- 浏览器渲染一个页面的时间线
浏览器请求页面的流程,这里我们只讨论无缓存的情况下请求一个全新页面的流程:
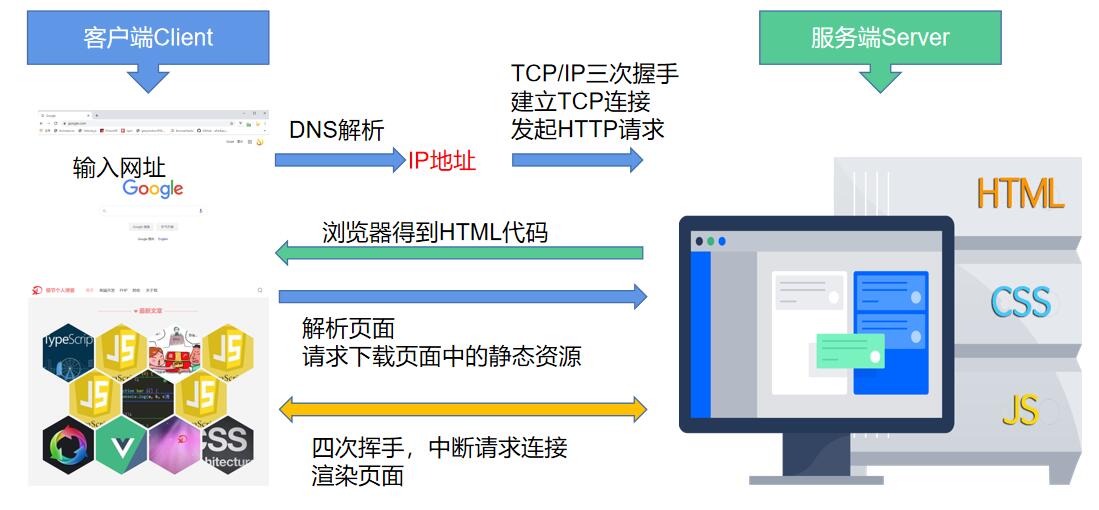
浏览器渲染页面的时间线指的是 浏览器从开始加载页面到整个页面加载完全结束这一过程中按顺序发生的每一件事情的总流程。
- 生成document对象(#document),此时JS就起作用了;
- 解析文档(从文档第一行阅读到最后一行),同时构建DOM树,此时
document.readyState为loading(第一阶段,加载中); - 遇到
link开启新线程,异步加载外部css文件;遇到<style>标签则构建CSS树(与DOM树同时); - 遇到没有设置异步加载的
<script>标签,会阻塞文档解析,等待JS脚本加载并执行完毕后,继续解析文档; - 遇到异步加载的
<script>标签,异步加载JS脚本并执行(设置async的才会执行,defer 不会立即执行),不阻塞解析文档(不能使用document.write()); - 遇到
<img>标签,会先解析节点,如果有src,创建加载线程,异步加载图片资源,不阻塞解析文档; - 文档解析完成(同时):
document.readyState为interactive(第二阶段,解析完成); - 文档解析完成(同时):设置了
defer的脚本按顺序执行; - 文档解析完成(同时):触发
DOMContentLoaded事件,程序从同步脚本执行阶段变为事件驱动阶段; - 设置了
async的脚本加载并执行完成、<img>等资源加载完毕后,触发onload事件,document.readyState为complete(第三阶段,文档加载完成)。
TCP 断开连接为什么要四次
第一次挥手的时候,发送了FIN包,服务器接收到以后,表示客户端不会再发送数据了,但还能接收数据。这时服务器先向客户端发送确认包,并且确认自己是否还有数据没有发送给客户端,这个确认阶段是CLOSE-WAIT,所以在中断等待2(FIN-WAIT-2)和CLOSE-WAIT的开始和结束需要各发送一个包,状态开始时向客户端发送的包是确认收到来自客户端的FIN包,状态结束时向客户端发送的是确认数据已经完整发送,所以是四次挥手。
四次挥手是服务器会先断开链接。
get 和 post 的区别
- GET主要用来获取数据,POST主要用于传输数据到后端进行增、删、改数据,提交表单;
- GET的数据在请求体中是查询字符串参数(Query String Parameters),而POST的数据在请求体中是表单数据(Form Data);
- POST更安全:不会作为URL的一部分;不会被缓存、保存在服务器日志和浏览器记录中;
- POST发送的数据量更大,GET有URL长度限制(IE:2083字符;Firefox:65536字符、Chrome:8182字符、Safari:80000字符、Opera:190000字符);
- POST能发送更多数据类型,而GET只能发送ASCII字符;
- POST比GET速度慢:
- POST请求包含更多的请求头;
- POST接收数据之前会先将请求头发送给服务器确认(服务器接收请求返回100 Continue),然后发送数据(服务器返回200 OK);而GET会一并发送,无需确认;
- GET会进行数据缓存,而POST不会;
- POST不能进行管道化传输。
- GET请求必须遵守幂等性,从HTTP请求上来看,GET只能获取数据;而POST请求一般不遵守幂等性。
跨域
我想知道什么?
- 为什么会出现跨域?
- 同源策略是什么?
- 跨域的解决方案
很多人上来就直接回答跨域的解决方案,却忽略掉了出现跨域的原因的解答。
为什么出现跨域?
Web浏览器只允许在两个页面有相同的源时,第一个页面的脚本才能访问第二个页面里面的数据。
同源策略是什么?
同源策略SOP是浏览器的一个安全功能,不同源的客户端脚本在没有明确授权的情况下,不能读写对方资源。
只有同一个源的脚本才会被赋予dom、读写cookie、session、ajax等操作的权限。
源 = 协议 + 域名 + 端口。
只有三者都一致的情况下,才会被视为同源。 只要有JS引擎的浏览器都使用同源策略。
页面中不受同源策略限制的项:
- 页面的超链接:
[百度一下,你就知道](https://www.baidu.com/); - 重定向页面
- 表单的提交
- 资源引入:
srcipt:src、link:href、img:src、iframe:src
解决方案
- 服务器中转请求;
- 设置基础域名 + iframe
- window.name + iframe
- hash + iframe
- postMessage + iframe
- 服务端设置 CORS
- jsonp
- flash
详情请看:前端网络基础
开放性问题
事实上,开放性问题的作用也是很大的,当两个面试者技术差不多的情况下,开放性问题回答得越好,那么在面试官中的印象分也更高,直接影响到你是否可以入职(当然薪资这一块更重要)。
在项目中有没有遇到过一些比较难的问题
但凡有过工作经历的开发人员,或多或少都会遇到过一些棘手的问题。哪怕只是困扰了你一个小时,这也算是比较难的问题,这些问题需要自己平时记录积累;面试官更感兴趣的是你如何解决这些问题,而并非问题本身。
忌回答没遇到过
如何学习新技术
这个问题主要是想知道你的学习能力如何。
请不要回答只会看一些视频教程,不喜欢看文档或看书之类的,哪怕你真的不喜欢看,或者不看。
关于简历
前前后后看了五、六十份简历,目前为止还是没有遇到过能令我眼前一亮的简历。
技能部分
很多人都罗列不少的技能,动不动就是熟练、精通,然后一问三不知;更有甚者连一些技术名词都是错的,难道自己写简历的时候不检查的吗?
虽说多放点技能容易通过HR的简历筛选,但你在给到面试官的那份简历,还是希望从实际出发:
- 前面几条尽可能地匹配公司招聘要求的技术;
- 写在简历上的技术,虽说不需要100%都能回答正确,但至少被问到的能回答出大部分;
- 技术名词的正确性,以及相关的技术能放到同一条。
我甚至遇到过问我要回简历看一下的,说不清楚我在问什么,我明明是按照他简历上写的技术问的,这就相当尴尬了。
项目经验部分
我不是非要问你技术上的问题,而是你的项目经验基本上都是流水账,让人找不到想要问的内容。
虽说不强求你完全遵循STAR法则,但你也别光说在xx项目做了哪些模块,然后全篇都是这种流水账。至少写写做这些模块用到了哪些技术,或者说解决了哪些问题。
如果你简历上写到将一个原本需要100s加载出来的页面优化到1s加载,那不得直接50K到手?
简历的排版
虽说没有规定使用什么格式来写简历,但是一些基本的排版还是需要的。求求你们,不要上一页就漏个标题,下一页放内容这种形式了,然后最后一页还留80%的空白。你让面试官不爽了,那最后只能是等通知!!!
面试造火箭,工作拧螺丝
曾经,我也吐槽过这点。
现在我从一个业余面试官的角度告诉你,为什么需要你造火箭。
首先,招人进来就是同事,虽说cv大法也能胜任,但是我不想招个人进来只会cv,甚至说配个环境都要跑过来问我????
其次,公司招人的标准是钱少技术好稳定三连,仅仅从一份简历上的内容不足以看出一个面试者的水平,所以才需要问更多的问题来决定相应的分数。
很多时候,面试官问得深入并不是想问倒你,而是想知道你的真实水平到底在哪里。
最后,如果面试官只是简简单单地问了一些内容而给你打了一个高分,公司招进来之后发现你其实只是一个cv工程师,那么会令到公司怀疑面试官的水平。
所以,虽然我也不想造火箭,但是我必须得让你会造火箭!
写在最后
非常感谢,回去等通知吧,我们会在三个工作日内再跟你联系!